跳至主要內容
標籤:
Selenium
【爬蟲筆記】Python Selenium Webdriver異常問題集
最後更新時間
10 4 月, 2020
【爬蟲筆記】如何在 GoogleComputeEngine 上運行 selenium 爬蟲
最後更新時間
10 4 月, 2020
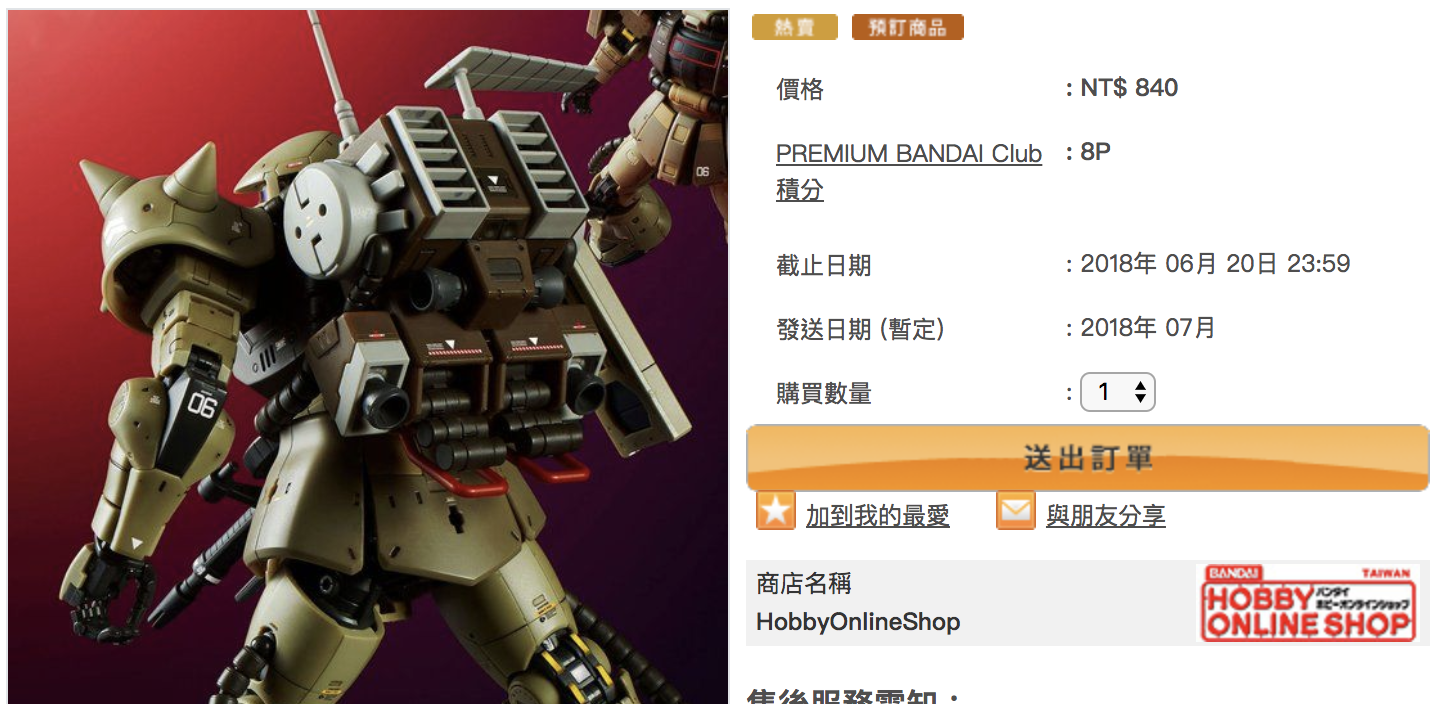
[爬蟲筆記] Python Selenium 爬蟲教學:實作商品庫存爬取
最後更新時間
10 4 月, 2020