
目錄
一. 為什麼需要 Concurrency ?
簡單來說 Concurrency Programming 就是能在同一時刻做兩件以上事情的能力,例如使用不同 CPU 分別運行程式來提高效率 ,或是當程式在等待執行結果時 (如等待 request 請求),先執行其他程式函式 (Coroutine),把浪費的 CPU 週期充分利用!
我們來看看 Golang 開發者之一 Rob Pike 對 Concurrency 的定義:
Concurrency is about dealing with lots of things at once.
Concurrency is not Parallelism – Rob Pike
Parallelism is about doing lots of things at once.
什麼是 Concurrency?
Concurrency 是指有同時開始處理多個任務,就像是有一位廚師同時在備料和煮麵,過程中會不斷地切換任務。
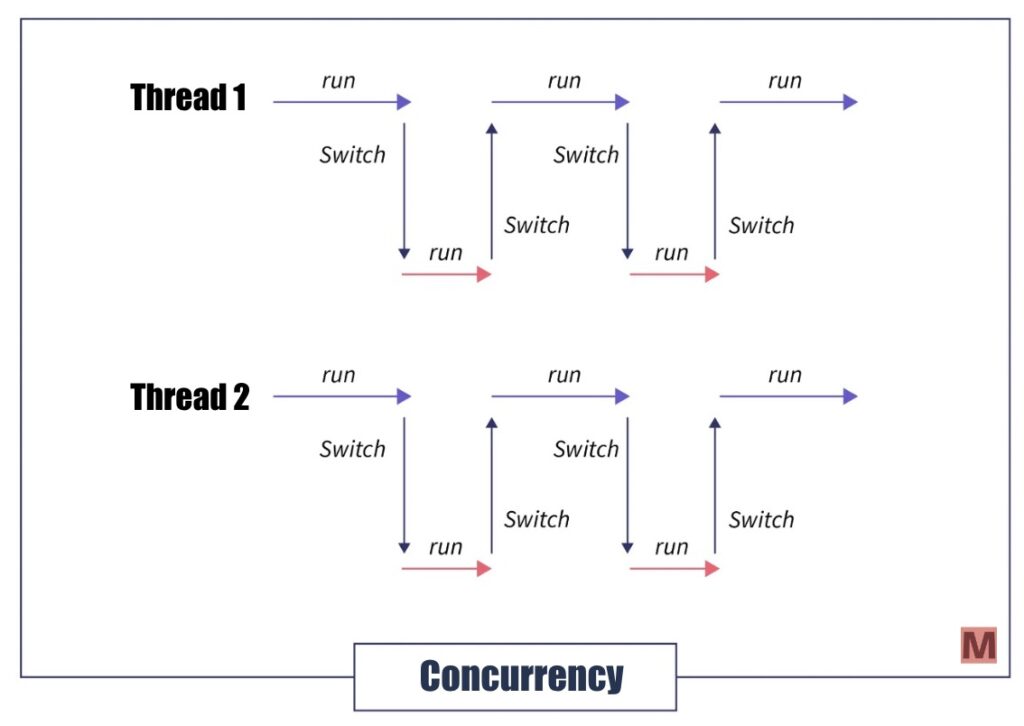
在 Python 中實現 Concurrency 可以用 Python 內建模塊(module) threading,或 Python 內建模塊 (module) asyncio 來達到同時開始處理多個任務,我們會在這篇文章後半段介紹 threading 和 asyncio 的差別。
1. threading (執行緒/線程) 使用方式:
- 可以參考我寫的【Python教學】淺談 Multi-threading 使用方法
- 也很推薦 realpython 寫的 threading 介紹 – An Intro to Threading in Python
2. asyncio – coroutine (協程 / 微線程) 使用方式:
什麼是 Parallelism?
Parallelism 是指在同一時間執行多個操作,就像是同時有兩位廚師,一位負責處理備料,一位負責煮麵任務。
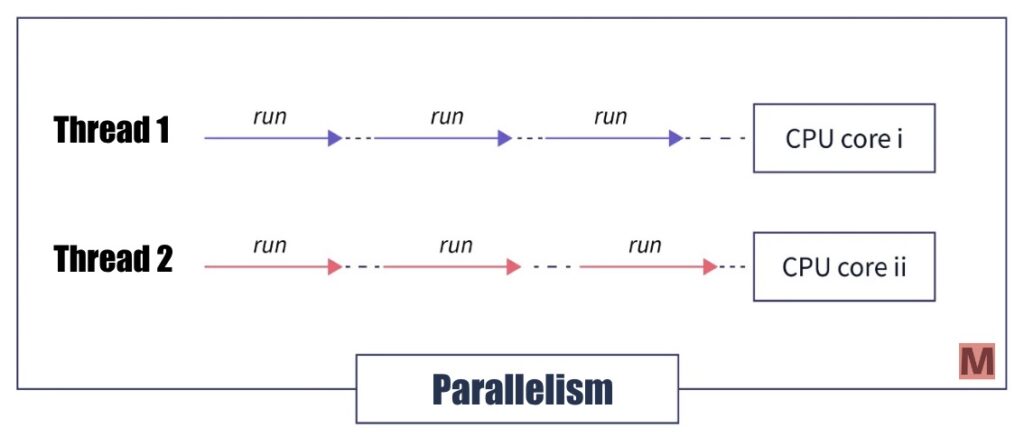
在 Python 中實現 Parallelism 可以使用 Python 內建模塊 (module) multiprocessing。
1. multi-processing 使用方式,可以參考我寫的以下兩篇:
了解了 Concurrency 與 Parallelism 的差異後,我們接下來介紹,在 Python 是如何實現 Concurrency 和 Parallelism。
二. Concurrency 與 Parallelism 之間選擇
假設我們今天是爬蟲的任務,一次會需要對網頁執行大量的 request,我們直接寫三種版本 (Multi-threading、Multi-processing 和 Async IO) 的 code 來看結果:
接下來我們會將爬取蝦皮商品頁共 54,870 頁,來執行 I/O Bound 的問題進行 Multi-threading、Multi-processing 和 Async IO 在執行時間上、記憶體和 CPU 負載進行比較。
1. 執行程序時間比較
此次共爬取 54,870 頁面,關於 Coroutine 的 number 我們設定的是 Semaphore 信號來限制 Coroutine 的併發量,而關於 Multi-threading 和 Multi-processing 的 number 則是 pool 內的數量。
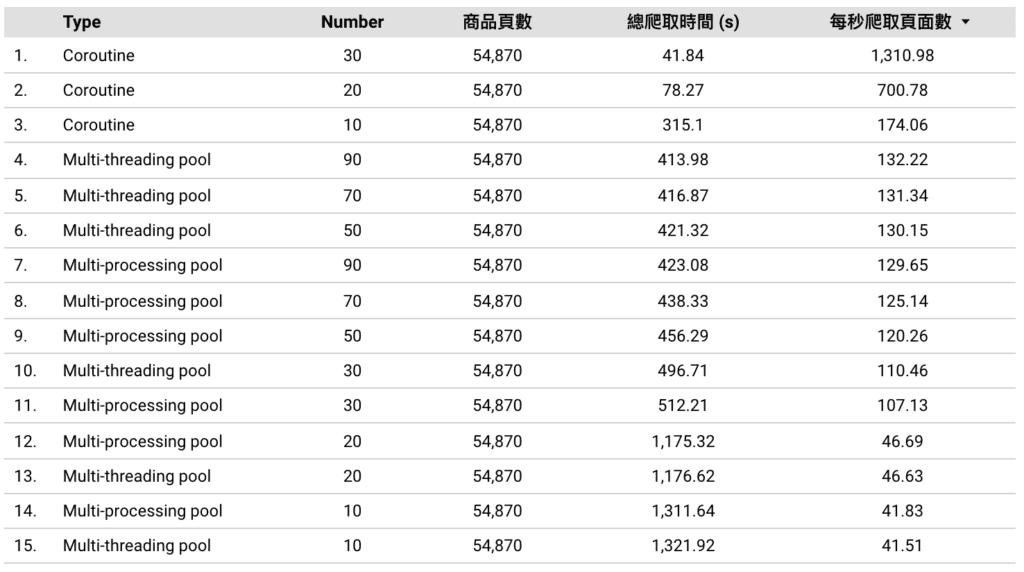
可以看到 Coroutine 在 Semaphore 設定為 30 時,每秒爬取 1310 頁,總共花費 41 秒爬完設定的 54,870 頁。
而 Multi-threading pool 在設定為 90 時,增加 pool 數量來提升執行效率已接近趨緩,故測試 pool 數量最終停留在 90,成績為每秒爬取頁面 132 頁,總共花費 413 秒爬完 54,870 頁。
最後 Multi-processing pool 在設定為 90 時,增加 pool 數量來提升執行效率已接近趨緩,故測試 pool 數量最終停留在 90,成績為每秒爬取頁面 129 頁,共花費 423 秒爬完 54,870 頁。
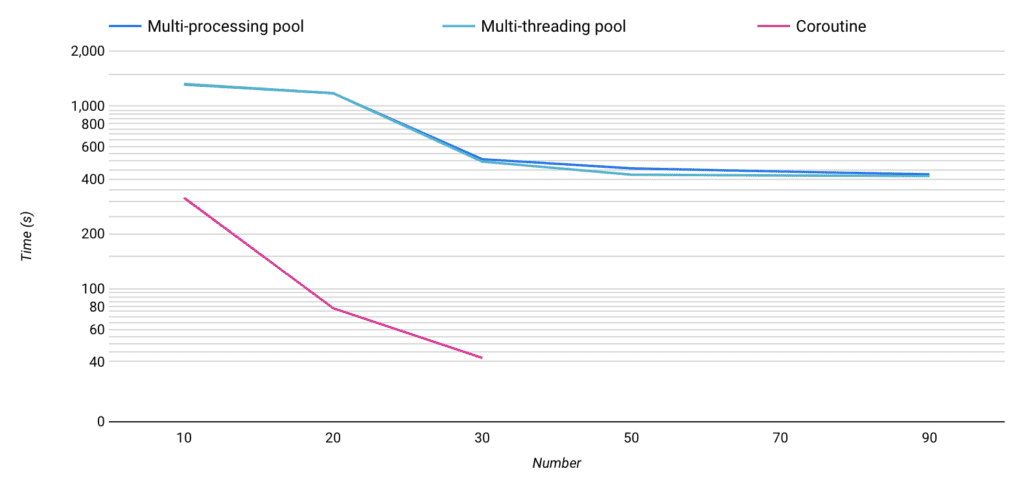
在時間上相較下來 Coroutine (41秒) > Multi-threading pool (413秒)> Multi-processing pool (423秒),在比較執行時間這個環節上由 Coroutine 大勝。
2. 記憶體和 Load average 負載比較
我們使用 htop 來進行這次的記憶體和 CPU 使用情況分析:

以上圖為例:
右邊區塊的 Load average 3.49 22.15 33.31 的三個數字分別代表了系統 1 分鐘、5 分鐘和 10 分鐘平均負載的情況。
而左邊區塊的 1 2 3 4 則顯示了目前 CPU 使用的百分比、Mem 代表記憶體和 Swp 為記憶體交換空間。
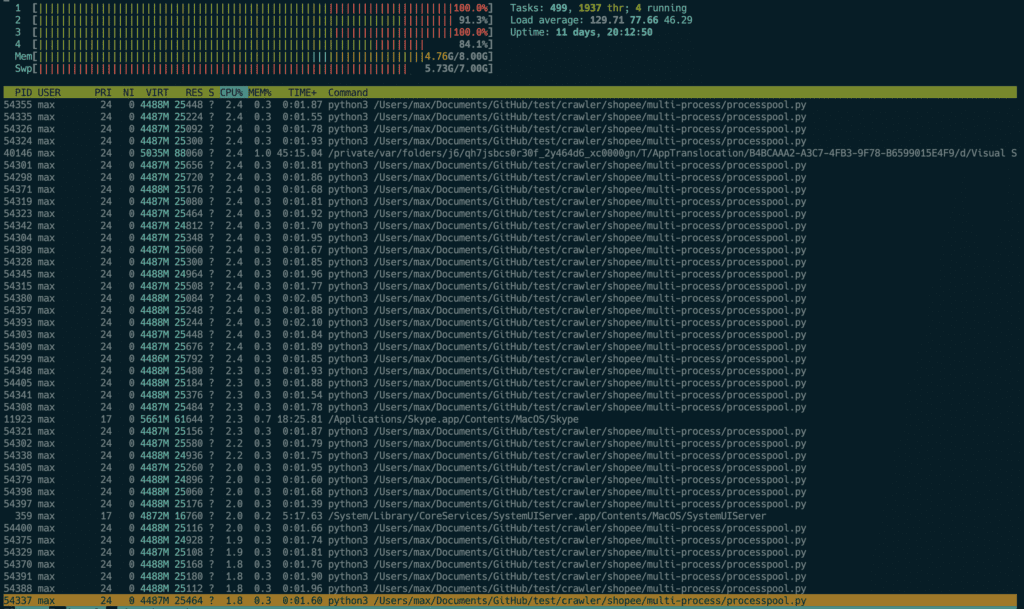
2.1 Multi-processing-pool (多處理程序池/多進程池)
當 Processing Pool 設定為 90 時,執行程式時可以看到:
- Load average 近一分鐘平均負載為 129.71
- Memory 記憶體為 4.76 G
2.2 Multi-threading-pool (多線池/多執行緒池)
當 Threading Pool 設定為 90 時,執行程式時可以看到:
- Load average 近一分鐘平均負載為 21.66
- Memory 記憶體為 4.40 G

2.3 Coroutine (協程/微線程)
當 Semaphore 設定為 30 時,執行程式時可以看到:
- Load average 近一分鐘平均負載為 2.17
- Memory 記憶體為 4.53 G

在 Load average 近一分鐘平均負載相較之下,Coroutine (2.17) < Multi-threading-pool (21.66) < Multi-processing-pool (129.71)
面對 I/O Bound 的爬蟲問題時,無疑的 Coroutine 相較其他兩者尤佳。
▍而關於更多有關 Coroutine (Async IO) 的操作可以參考以下文章:
- 【Python教學】淺談 Coroutine 協程使用方法
- 【Python教學】Async IO Design Patterns 範例程式
- 【實戰篇】 解析 Python 之父寫的 web crawler 異步爬蟲
最後~
▍回顧本篇我們介紹了的內容:
- 為什麼需要 Concurrency
- Python 中實現 Concurrency 的方法
- 面對 I/O Bound 爬蟲問題選擇
- 執行程序時間比較
- 記憶體和 Load average 負載比較
- Multi-processing-pool (多處理程序池/多進程池)
- Multi-threading-pool (多線池/多執行緒池)
- Coroutine (協程/微線程)
▍關於與 Concurrency Programming 相關其他文章,可以參考:
那麼有關於【Python教學】淺談 Concurrency Programming 的介紹就到這邊告一個段落囉!有任何問題可以在以下留言~