跳至主要內容
Max行銷誌
行銷、數據分析、與 Python
Python
Git
Flask
Crawler
GTM
Data Analytics
Dashboard
About
搜尋關鍵字:
Max行銷誌
行銷、數據分析、與 Python
Python
Git
Flask
Crawler
GTM
Data Analytics
Dashboard
About
Max行銷誌
行銷、數據分析、與 Python
搜尋關鍵字:
分類:
Python 機器學習
文字模糊比對:SequenceMatcher
最後更新時間
6 11 月, 2022
GridSearchCV 和 RandomizedSearchCV 的差異
最後更新時間
29 9 月, 2022
效能指標 Accuracy, Recall, Precision, F-score
最後更新時間
12 9 月, 2022
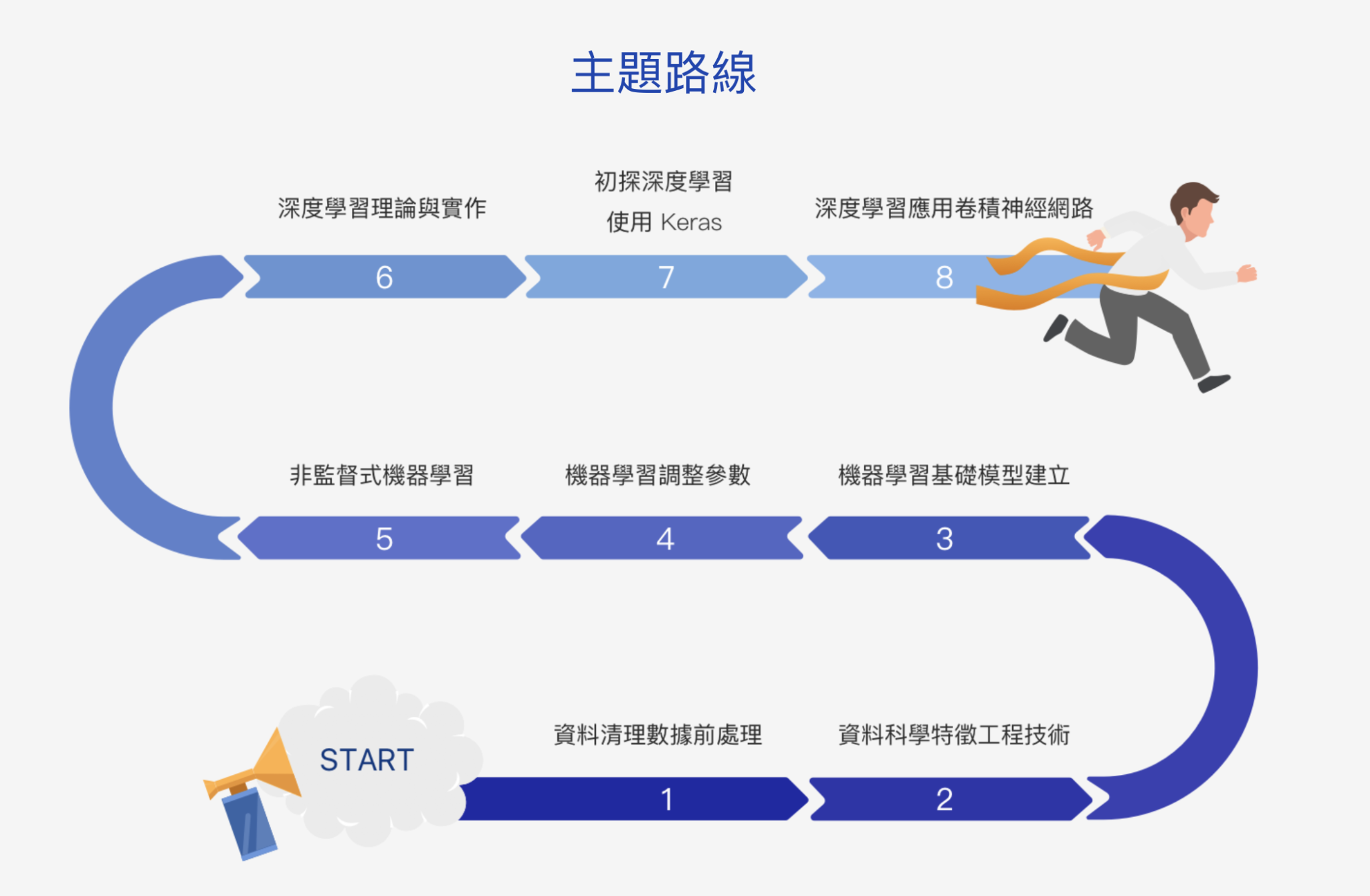
[百日馬拉松] 機器學習-特徵工程
最後更新時間
2 1 月, 2020
[百日馬拉松] 機器學習-資料清理
最後更新時間
2 1 月, 2020
[關聯分析] Apriori演算法介紹 (附Python程式碼)
最後更新時間
10 4 月, 2020