
SequenceMatcher 是從兩個序列中,找出最長連續的序列,可以排除設定的 junk 元素,計算的空間複雜度是 O(n^2),使用上不需要額外安裝套件,是 python 內建的函式中 difflab 所提供的 class.
實作
|
1 2 3 4 5 6 7 8 9 10 11 12 |
import difflib sequence1 = "apple iphone - price and deals" sequence2 = "iphone 14 price" result = difflib.SequenceMatcher(None, sequence1 ,sequence2) print(result.get_matching_blocks()) >> [Match(a=6, b=0, size=7), Match(a=14, b=9, size=6), Match(a=30, b=15, size=0)] print(result.ratio()) >> 0.5777777777777777 |
當我們 print get_matching_blocks 方法時,可以看到有被比對到的區塊,[Match(a=6, b=0, size=7), Match(a=14, b=9, size=6), Match(a=30, b=15, size=0)]
- a: 代表 sequence1 的開始位置
- b: 代表 sequence2 的開始位置
- size: 代表兩序列相同的長度
SequenceMatcher 的計算方式
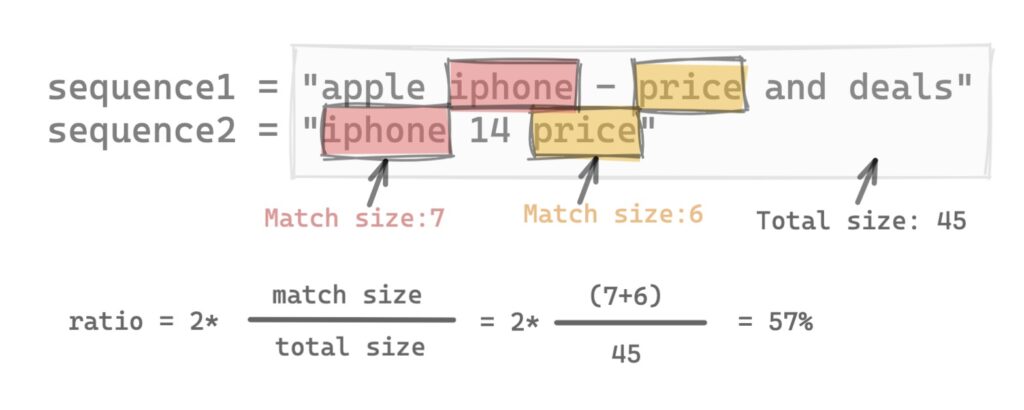
當我們 print ratio() 時,可以計算出兩序列的相似度,公式如下:2* matches / total number of elements,所以兩序列總共 match 的元素有 13,而全部的元素有 45,所以相似度是 2*13/45 = 0.57777
相關延伸閱讀:
- Longest common subsequence (Leetcode #1143 Medium)
- Python difflib.SequenceMatcher (Python document)