
GridSearchCV 是將你列出的所有條件參數都跑過一次,再給予最佳的參數;而 RandomizedSearchCV 則是依據 n_iter 設定的數字,隨機抽取來跑 model
目錄
從程式碼來看
可以看到 GridSearchCV 和 RandomizedSearchCV 都是繼承了 BaseSearchCV,然後覆寫了_run_search 的方法,差別在於處理 param_distributions 是使用 ParameterSampler 或 ParameterGrid
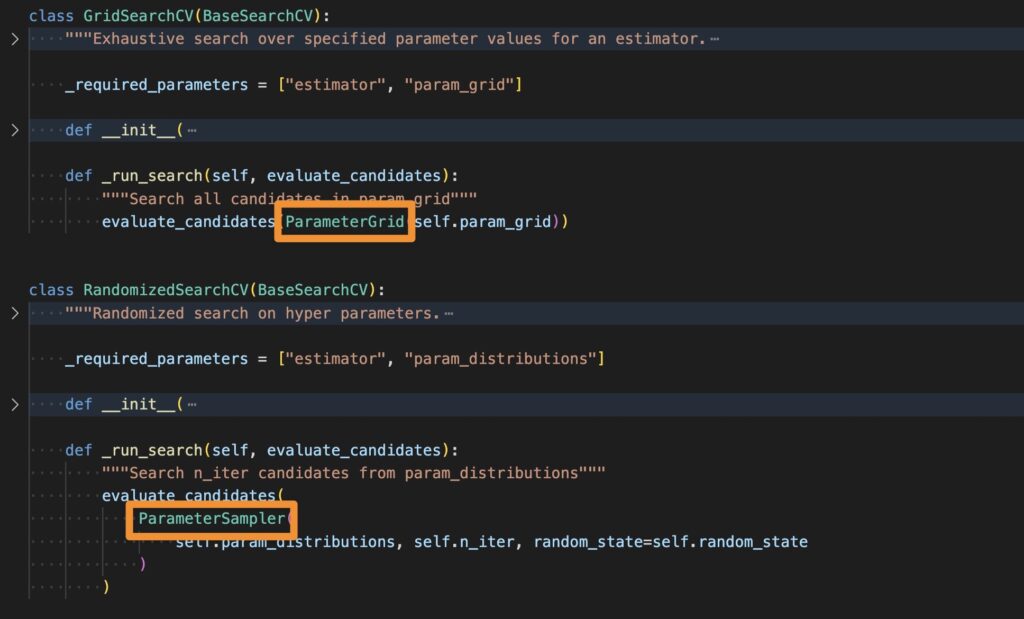
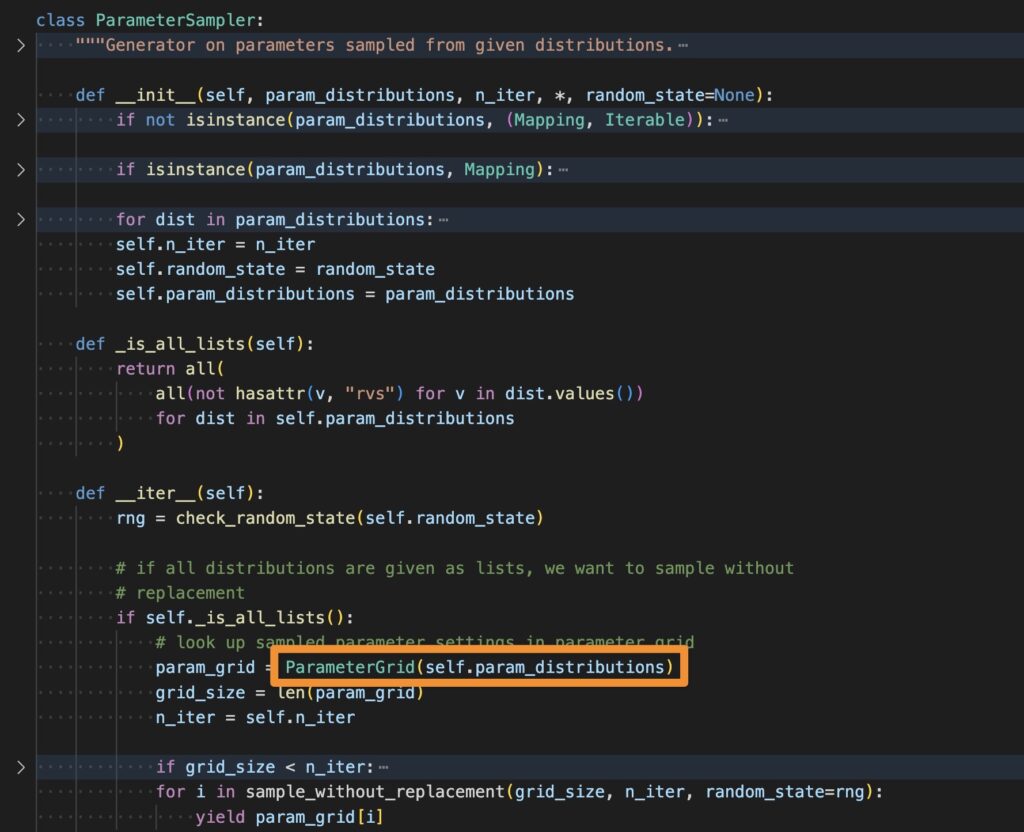
接下來我們再細看 ParameterSampler 和 ParameterGrid 的差異,可以看到 ParameterSampler 裡面還是使用 ParameterGrid 來處理傳入的參數,只是多了 n_iter 來隨機抽取 n 組參數
最後我們來看 ParameterGrid,在 __getitem__ 裡面將我們傳入的 param_grid 打散,組成接下來要訓練模型的參數
|
1 2 3 4 5 6 |
grid = [{'kernel': ['linear']}, {'kernel': ['rbf'], 'gamma': [1, 10]}] list(ParameterGrid(grid)) >>> [{'kernel': 'linear'}, {'kernel': 'rbf', 'gamma': 1}, {'kernel': 'rbf', 'gamma': 10}] |

動手試試看
1. 安裝 scikit-learn
首先需要安裝 scikit-learn 套件,以下是 Windows、macOS 和 Linux 安裝方式:
|
1 |
$ pip install scikit-learn |
2. GridSearchCV
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 |
from sklearn.svm import LinearSVC from sklearn.model_selection import train_test_split from sklearn.model_selection import GridSearchCV param = { "C": [1.3, 1.5, 1.8, 2.3, 2.5, 2.8], "dual": (True, False), "random_state": [666], } x_train, x_test, y_train, y_test = train_test_split( data.drop(["Category"], axis=1), data["Category"], random_state=0, test_size=0.2, ) main = GridSearchCV(LinearSVC(), param, refit=True, verbose=3, n_jobs=-1) main.fit(x_train, y_train) print(main.best_score_) print(main.best_params_) |
3. RandomizedSearchCV
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 |
from sklearn.svm import LinearSVC from sklearn.model_selection import train_test_split from sklearn.model_selection import RandomizedSearchCV param = { "C": [1.3, 1.5, 1.8, 2.3, 2.5, 2.8], "dual": (True, False), "random_state": [666], } x_train, x_test, y_train, y_test = train_test_split( data.drop(["Category"], axis=1), data["Category"], random_state=0, test_size=0.2, ) main = RandomizedSearchCV(LinearSVC(), param, n_iter=5) main.fit(x_train, y_train) print(main.best_score_) print(main.best_params_) |