
目錄
Apriori演算法原理
思考路徑:
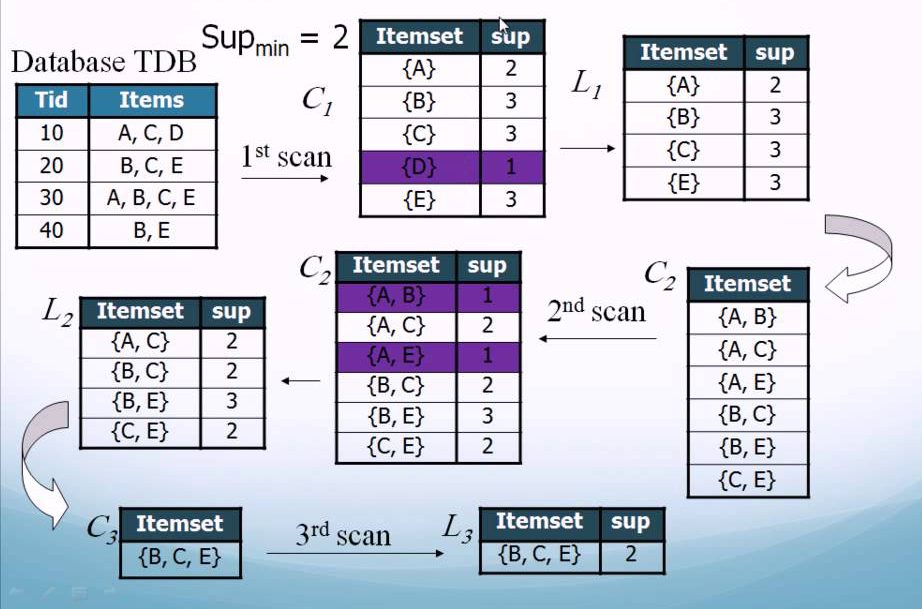
A priori在拉丁語中指「來自以前」,Apriori是經典的挖掘資料關聯性演算法,採用迭代的方法先搜索出第一項集的各Item支持度,並剪去低於最小支持度的第一項集,得到第二項集後再剪去低於最小支持度的第二項集,依次類推下去直到無法找到項集為止。
Apriori定律1:
假設一個集合{A,B}大於等於最小支持度(Min_Support),則他的子集{A},{B}出現次數必定大於等於最小支持度(Min_Support)
Apriori定律2:
假設集合{A}出現次數小於最小支持度(Min_Support),則他的任何集合如{A,B}出現的次數必定小於最小支持度(Min_Support)
評估指標
1. 支持度(Support):
支持度表示為 item-set 在整個 AllSamples 中出現的頻率,公式為:
Support(X) = number(X) / number(AllSamples)
Support(X,Y)=number(XY)/number(AllSamples)
2. 置信度(Confidence):
置性度表示當事件X發生的情況下,同時會發生Y的可能性,公式為:
Confidence(X→Y) = P(Y|X) ,= P(X∩Y) / P(X)
3. 提升度(Lift):
提升度表示當事情X發生的情況下,同時發生Y的可能性,且只看Y發生的機率,提升度反應了X與Y的關聯性,提升度>1或越高表示越相關,提升度=1表示為互相獨立,提升度<1或越低代表負相關性越高。公式為:
Lift(X→Y) = Confidence(X→Y) / P(Y) = P(Y|X) / P(Y)
4. 舉例:
堅果對腰果的置信度為40%,支持度5%,提升度3。代表在購物數據中,共有5%的用戶既購買了腰果又買了堅果;同時買堅果的用戶有40%會購買腰果,堅果和腰果是正關係。
附上程式碼
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
from apyori import apriori data = [['r', 'z', 'h', 'j', 'p'], ['z', 'y', 'x', 'w', 'v', 'u', 't', 's'], ['z'], ['r', 'x', 'n', 'o', 's'], ['y', 'r', 'x', 'z', 'q', 't', 'p'], ['y', 'z', 'x', 'e', 'q', 's', 't', 'm']] association_rules = apriori(data, min_support=0.16, min_confidence=0.2, min_lift=3, max_length=2) association_results = list(association_rules) for item in association_results: pair = item[0] items = [x for x in pair] print("Rule: " + items[0] + " -> " + items[1]) print("Support: " + str(item[1])) print("Confidence: " + str(item[2][0][2])) print("Lift: " + str(item[2][0][3])) print("=====================================") |
數據分析相關延伸閱讀:
Python相關教學延伸閱讀:
- 【Python教學】 pip install 指令大全
- 【Python教學】 寫給新手的 Python 入門基礎操作
- 【Python教學】 使用 pyenv 和 virtualenv 打造 Python 環境配置
- 【Git教學】 寫給Git初學者的入門 3 步驟
- Visual Studio Code 必備的 5 個擴充和小常識
那 [關聯分析] Apriori演算法介紹 (附Python程式碼) 就到這邊,感謝收看,有關Max行銷誌的最新文章,都會發佈在Max的Facebook粉絲專頁,如果想看最新更新,還請您按讚或是追蹤唷!